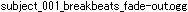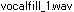無難なBMSの指針
- 2024年2月20日:7-Zip 24.01 beta
- 2024年1月21日:7-Zip 23.01, U+FA19撤去, 生の代用対をコードポイント表記に変更, タイ文字先頭にゼロ幅空白挿入
- 2021年11月26日:7-Zip 21.02 alpha以降はZIP書庫のfilenameをUTF-8で格納するようになったためcu=on不要
- 2020年3月26日:Unicodeの諸問題にUbuntu 19.10について追記、サンプル書庫を追加
- 2020年3月25日:Windows 7へのパッチ適用状況と、新しい7z書庫をWinRARで展開する場合について追記
- 2020年2月27日:Windows 10 1903以降のメモ帳と、Windows NT 4.0のメモ帳について追記、その他修正
- 2018年6月1日:[HTTPS] 7-Zip, Explzh, ZipExtractor
- 2018年5月15日:UTF-8 BMSではなくBMSONを推奨する段落を追記
- 2017年10月22日:WinRAR (HTTPS)
- 2017年9月21日:7-Zip 17.01 beta
- 2017年9月20日:charatbeatHDX v1.15, μBMSC 3.2,
<meta charset="utf-8" /> (bye Lynx 2.8.6 rel.4TH)
- 2017年8月15日:WinRAR 5.50, Explzh Ver.7.55
- 2017年6月17日:WinRAR 5.50 beta 4
- 2017年5月24日:WinRAR 5.50 beta 3
- 2017年5月6日:WinRAR 5.50 beta 2
- 2017年4月30日:7-Zip 17.00 beta
- 2017年4月14日:WinRAR 5.50 beta 1
- 2017年4月8日:Explzh Ver.7.54
- 2016年12月20日:Windows NT 4.0のメモ帳のUnicodeをUTF-16LEでなくUCS-2に訂正
- 2016年12月11日:Explzh Ver.7.52
- 2016年11月10日:Explzh Ver.7.51
- 2016年11月2日:Explzh Ver.7.50
- 2016年10月26日:Explzh Ver.7.48
- 2016年10月13日:Explzh Ver.7.47
- 2016年10月5日:7-Zip 16.04, Explzh Ver.7.46
- 2016年9月29日:7-Zip 16.03
- 2016年9月25日:Explzh Ver.7.45
- 2016年9月12日:Explzh Ver.7.43
- 2016年9月6日:Explzh Ver.7.41
- 2016年9月5日:Explzh Ver.7.40
- 2016年9月1日:Explzh Ver.7.35, charatbeatHDX v1.13, WinRAR 5.40
- 2016年7月2日:WinRAR 5.40 beta 3
- 2016年6月14日:Explzh Ver.7.34
- 2016年6月12日:Explzh Ver.7.33
- 2016年6月7日:メモ帳のUnicode対応状況を追記。Windows 95対応版WinRARを3.93から3.80に訂正
- 2016年5月31日:WinRAR 5.40 beta 2
- 2016年5月21日:7-Zip 16.02
- 2016年5月20日:7-Zip 16.01
- 2016年5月11日:Explzh Ver.7.32, WinRAR 5.40 beta 1, 7-Zip 16.00
- 2016年4月17日:charatbeatHDX v1.12, BMIIDXView2015 v3.04 (2016年4月12日)
- 2016年4月10日:freett URL修正
- 2016年3月16日:charatbeatHDX v1.11 (2016年3月14日)
- 2016年3月7日:charatbeatHDX v1.10 (2016年2月14日)
- 2016年2月5日:WinRAR 5.31
- 2016年1月9日:誤字修正
- 2016年1月3日:没書
ファイル名に非ASCII文字を使わないでください
ギリシャ語Windows 8.1のメモ帳で書かれエクスプローラーの圧縮フォルダーに送られた、ごく普通のBMSのZIP書庫。ギリシャ語環境ではBMS関連ソフトウェアによって正常に再生されます。
非ギリシャ語環境では文字化けし、ファイル名に不可視の制御文字が混入したり、エクスプローラーの圧縮フォルダーからファイルが見えず展開できなくなる場合があります。なぜ文字化けするのかというと、非ASCII文字を符号化・復号化する仕組みが言語環境ごとに異なるからです。
メモ帳による符号化
| バイト列 | CF | C4 | D6 | C1 |
|---|
| 米国英語 | Ï | Ä | Ö | Á |
|---|
| タイ語 | ฯ | ฤึ | ม |
|---|
| 日本語 | マ | ト | ヨ | チ |
|---|
| 簡体字 | 夏 | 至 |
|---|
| 韓国語 | 謳 | 逞 |
|---|
| 繁体字 | 狦 | 祫 |
|---|
圧縮フォルダー
| バイト列 | 8E | 83 | 94 | 80 |
|---|
| 米国英語 | Ä | â | ö | Ç |
|---|
| タイ語 | | | ” | € |
|---|
| 日本語 | 祉 | 楳 |
|---|
| 簡体字 | 巸 | 攢 |
|---|
| 韓国語 | 럠 | |
|---|
| 繁体字 | | |
|---|
- Windowsのシステムロケールは、環境ごとに異なります。→ Code Page Identifiers
- Windows 10 October 2018 Update 1809までのメモ帳や、大多数のBMS関連ソフトウェアは、暗黙的にANSIコードページを使用します。(Windows 10 May 2019 Update 1903以降のメモ帳は、既定の文字エンコーディングとしてANSIコードページではなく「Byte Order Mark無しのUTF-8」を使用します。)
- エクスプローラー圧縮フォルダーは、ZIP仕様書に寄せてOEMコードページを使用します。
東アジアで鳴るBMSは、西欧で鳴りません。西欧ではANSIとOEMが異なるからです。- 東アジア環境でBMS作成者の期待通りに音声が再生される「OEM符号化ZIP圧縮された、非ASCII名のファイルを参照するBMS」は、西欧環境では音声が再生されません。東アジアWindows環境ではANSIとOEMが同一のコードページを用いるため、「BMSファイル上の非ASCII定義名(ANSI)」は幸運にも「ZIPに格納され展開された非ASCIIファイル名(OEM)」と一致します。たとえ文字化けするにしても定義名とファイル名は同じ規則に沿って同じ文字に化けるので、化けた先が「そのコードページが扱える印字可能文字」である限り、音声は再生されます。しかし西欧Windows環境ではANSIとOEMは別個のコードページが用いられます。東アジア産のOEM符号化ZIP書庫が西欧Windows環境で配慮なしに展開された場合、「BMSファイル上の非ASCII定義名」と「実際の非ASCIIファイル名」は別々の規則に沿って別々の文字に化けます。この場合、非ASCIIファイル名を持つ音声が再生される可能性は一切ありません。
気が利いた外部アーカイバーソフトウェアは使用者に文字化けを気づかせない場合があり、便利な一方で困った事態を引き起こしもします。展開時にフォルダー名の先頭部分が「ルモ・」に化けて、そのままRAR書庫としてTorrentパッケージに収録されてしまった例などが知られています。
OEM符号化ZIP
| バイト列 | D9 | D3 | FC | B3 |
|---|
| 米国英語 | ┘ | ╙ | ⁿ | │ |
| タイ語 | ู | ำ | | ณ |
| 日本語 | ル | モ | |
| 簡体字 | 儆 | U+E3BE |
| 韓国語 | 夢 | 幻 |
| 繁体字 | 棑 | U+E18B |
RAR内CP932バイト列
| バイト列 | D9 | D3 | 81 | 45 |
|---|
| 米国英語 | ル | モ | ・ |
| タイ語 | ル | モ | ・ |
| 日本語 | ル | モ | ・ |
| 簡体字 | ル | モ | ・ |
| 韓国語 | ル | モ | ・ |
| 繁体字 | ル | モ | ・ |
ASCIIだけが文字化けしません。ファイル名の非ASCII文字を目視で見つけるのは難しい場合があるので、BMSテキスト内を[^\t-~]などの条件で正規表現検索して確認しましょう。
ASCIIは文字化けしませんが、非ASCII文字の誤った復号化に巻き込まれる場合はあります。
| バイト列 | B6 | F3 | 2E | 77 | 61 | 76 |
|---|
| 韓国語 | 라 | . | w | a | v |
|---|
| 日本語 | カ | | w | a | v |
|---|
これは日本語Windows環境では、拡張子なしのファイル「カ・wav」になります。
言語環境を問わずにBMSを正しく再生させる方法は、いまのところ二つしかありません。(BMS形式にこだわる必要がない場合は、第三の方法も選択できます。)
- 非ASCIIファイル名を禁止します。この方法はMS-DOS BMSにさえ対応できます。
- さもなくば、BMSテキストをUnicodeで保存し、かつファイル名もUnicodeで圧縮します。
- 可能ならBMSON形式を用いる方法が、最も混乱を避けられます。
BMSテキストをUnicodeで保存する
Windows NT系のメモ帳(notepad.exe)は、NT 4.0以降はUnicodeをサポートしています。
- Unicodeを扱うBMSは、常にUTF-8を選択してください。SonorousはUTF-16を実装しません。
- BOMは事実上必須です。ruv-itやHDX/IIDXvは、BOMなしのUTF-8を認識しません。
- Windows 2000からWindows 10 October 2018 Update 1809までのメモ帳:
メモ帳でBMSファイルを開き、「名前を付けて保存」ダイアログの「文字コード」欄から「UTF-8」を選択して、保存してください。
- Windows 10 May 2019 Update 1903以降のメモ帳:
メモ帳でBMSファイルを開き、「名前を付けて保存」ダイアログの「文字コード」欄から「UTF-8 (BOM 付き)」を選択して、保存してください。
- Windows NT 4.0のメモ帳:
Windows NT 4.0のメモ帳はUTF-8を知りません。BOMつきUTF-16(Little Endian)の読み書きは可能です。メモ帳でBMSファイルを開き、「名前を付けて保存」ダイアログで「Unicode で保存する」をチェックして保存すると、BMSテキストはUTF-16LE (BOMつき)で符号化されます。
正確にいえば、Windows NT 4.0のファイルシステムはUCS-2を採用しているそうです。UCS-2は「基本多言語面限定のUTF-16」と考えることができます。UCS-2ではサロゲートペアは扱えないため、追加面に収録された絵文字などの類は一切扱えません。
……ということになっているはずなのですが、実際はファイルシステムから見えるバイトシーケンスがWindows 2000以降のそれと同一であれば特に問題は発生しないようです。
- iBMSC:
iBMSCはUnicodeをサポートしています。ただしBOMなしのUTF-8を自動認識しません。また音声プレビュー機能はANSIコードページで書き表わせるファイル名しか再生できません。保存は正しく行われます。
- μBMSC:
iBMSCの音声プレビュー機能に関する不具合はμBMSCで解消されました。またμBMSCでは既定のencodingが変更されたため、BOMなしのUTF-8を問題なく認識してくれるようになりました。そのかわり日本語や韓国語のBMSを開くと文字化けするようになりました。Encodingを指定して開き直すことで解決可能です。
- HDX/IIDXv:
HDX/IIDXvはUnicodeをサポートしています。ただしv1.18/v3.06時点では、冗長なバイト列を受け入れてしまいます。また基本多言語面にない文字は、HDX/IIDXvではCESU-8で符号化される必要があります。これは他の正しいUTF-8実装とは互換性がありません。
- LR2, BMSE/uBMplay, その他:
LR2やBMSEやuBMplayはUnicodeをサポートしていません。UTF-8のバイト列はANSIコードページで復号され、文字化けします。その結果、非ASCII名のファイルは参照に失敗します。#TITLEなどの文字列値が「現在の環境におけるANSIコードページでは記述できない文字」を含む場合、LR2のデータベースに良くない影響があるかもしれません。
Windows 10 April 2018 Update 1803以降(正しくはWindows 10 Redstone 4のInsider Preview以降)、システムロケールにUTF-8を選択できるようになりました。このオプションを有効化した環境では、LR2やBMSEやuBMplayがUTF-8符号化BMSを正しく再生できるようになり、そのかわり従来のANSIコードページで書かれた「非ASCIIファイル名を参照するBMS」が正しく再生されなくなります(期待通りには音が鳴らなくなったり文字化けしたりするようになります)。
以下の方法はもはや現代的ではありません。
BMSフォルダーに、ANSI版(古い文字符号化方式)とUnicode版を同梱する例を紹介します。
CP932.bms → “#TITLE _(:3 」∠ )_”CP932_readme.txt → “∠ is not a Shift_JIS character”Unicode_hide_from_LR2.zip\
UTF8BOM.bms → “#TITLE _(:3 」∠ )_”UTF8BOM_readme.txt → “∠ is not a Shift_JIS character”
このCP932符号化テキストは、韓国語環境では“#TITLE _(갌3 걐곙 )_”や“곙 is …”に文字化けします(CP932とCP949を自動判別してくれるruv-itなどは除く)。しかしUnicode版は文字化けしないので、元の文字を判断するための根拠になります。
前述の方法はもはや現代的ではありません。Unicode版BMSのかわりに、BMSON形式のファイルを同梱することを推奨します。「システムロケールがUTF-8でない従来環境のための、およびUTF-8を知らない旧型機種のための、ANSI版BMS」と、「新しいBMSON対応機種のためのBMSON」を同梱できれば、互換性が問題になる状況はほぼ避けられるでしょう。
余談:複数の符号化形式が混在する例
KBP2012「結界」から引用
| BMS | 韓国語 | 日本語 |
|---|
| #TITLE | 됌뙅둉 | 火結界 |
|---|
| #WAV01 | 0도.wav | 0オオ.wav |
|---|
#TITLEや#ARTISTはANSI(CP932, Windows-31J)なので、非日本語環境では文字化けします。#WAVはANSI(CP949, ks_c_5601-1987)なので、非韓国語環境では鳴りません。- 実際のファイル名はOEM(CP949, ks_c_5601-1987)なので、非韓国語環境で文字化けします。
感想欄でion_tracker氏が指摘しておられますが、ファイル名をASCIIのみで構成すれば、圧縮形式や符号化形式が何であれ、著者の意図通りにBMSが鳴ります。そうしないならBMSテキストの符号化形式は統一するべきだし、ファイル名やフォルダー名もUnicodeで圧縮しなければなりません。
(Unicode差分つき無断再配布: https://hitkey.nekokan.dyndns.info/Genkai-UTF8.zip )
ファイル名やフォルダー名もUnicodeで圧縮する
圧縮形式はRARが無難です(2002年5月版WinRAR v3.00以降がサポートするRAR2.9以上)。非ASCIIのファイル名を確実に格納できます。ファイル名の符号化形式は変則的ですが、基本的なバイト列はUTF-16LEの変形です。WinRAR v3.80まではWindows 95にも導入できます。Windows NT 4.0以降のNT系OSであれば、展開も確実に行えます。
7z形式も、非ASCIIファイル名をUTF-16LEで格納します。ただし7-Zip 15.14以降で作成された7z書庫をWinRAR 5.31以降で展開する場合は、7zxa.dllの最新版(7-Zip Extraに同梱)をWinRARインストールフォルダーに上書きしておく必要があります。おそらくWinRAR 5.40以降からはそうするまでもなくなっていました。WinRAR側か7-Zip側かわかりませんが問題が解決されたのだと思います。
じつのところZIP形式もUnicodeに対応していますが(7-Zip 21.02 alpha以降なら普通にZIP圧縮、それ以前の7-Zipならcu=onパラメータで作成)、Vista以前のエクスプローラーでそれを展開すると文字化けします(格納されたファイル名のUTF-8バイト列を、OEMコードページで復号するため)。またWindows 7ではKB2704299が必要です。2020年1月までの更新プログラムを全部適用しているWindows 7環境であれば、このパッチは不要です。Windows XPおよびそれ以前のエクスプローラー圧縮フォルダーは、deflate方式のZIP書庫にのみ対応しています。Windows Vista以降はdeflate64方式もサポートしています。
ギガバイト単位の巨大なBMSパッケージはRAR5で圧縮するのが良さそうです。分割圧縮可能、クイックオープンインフォメーションにより高速に展開可能、リカバリレコード付加可能、ファイル名をUTF-8バイト列で格納(バイナリを直接検索できます)。ただしWindows 95/98/Meは切り捨てることになります。WinRAR 5.x以降を導入できないWindows 2000上でも、7-Zipを用いればRAR5書庫を展開できます。2017年4月版WinRAR v5.50 beta 1以降、WinRARにおけるRAR圧縮の既定形式はRAR4からRAR5に変更されました。
Windows Vistaまでを切り捨ててよいなら、UTF-8符号化ZIP書庫が最良です。OSを問わず標準の機能で展開できるからです。LZMA方式で圧縮すれば、Windows 10のエクスプローラーでさえ展開できないので、誤ったファイル名が展開される心配はありません(ZIPを選ぶ意味もないけど)。
Unicodeの諸問題
Mac OS Xは内部ではファイル名を分解して扱います。「㍊」は「ミ + リ + ハ + ゙ + ー + ル」になります。これはUnicode NFD仕様の実装のひとつですが、実際にテストしないと結果を推測しがたい部分があります。「#WAV01 안녕.wav」(<U+C548> <U+B155>)は「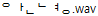
<U+110B U+1161 U+11AB> <U+1102 U+1167 U+11BC>)を参照できるのでしょうか?
もし参照できるとすれば、システムは等価性を考慮することになりますが、では次の例のようなファイル参照は最終的にどのように処理されるのでしょうか? 等価性を考慮しないWindows上では、三つの音声は当然ながら別個のファイルとして区別され、別々に鳴らされるわけですが……
#TITLE Han God
#BPM 140
#WAV01 神.wav // U+795E
#WAV02 示申.wav // U+FA19
#WAV03 神󠄀.wav // U+795E U+E0100
#00111:010203
(U+FA19はHTML仕様範囲外なので、例示では他の文字の組み合わせで代用しています)
検証用書庫は、Explzh v7.58で開くとファイルが一個見えなかったり(v7.99で確認したところ、いつのまにかどこかの版で修正されたようでした)、7-Zip 24.01 betaでZIP圧縮するとWinRARで正しく展開できなかったり、Windows環境に限定してさえデータ交換がうまくいきません。この書庫がMac OS X上で正しく展開されるのか、私にはわかりません。
なおUbuntu 19.10上のUNRAR 5.61 beta 1で、前述の検証用RAR4書庫は正しく展開されません。7z形式、RAR5形式、ファイル名がUTF-8で符号化されたZIP形式などの書庫であれば、Ubuntu上でもWindows上と同等のファイル名で展開されます。また前述のBMSを変換したBMSON(この段落の書庫に同梱)は、Ubuntu上でもWindows上でもbeatorajaによって同等に再生されます。
ファイルシステムの差異も無視できません。以下はWindowsとLinuxでの最長の名前の例です。
![[Windows] D:\𛀀󠄀゙(50回繰り返し).txt](img/use-ascii-4.png)
![[Linux] 𛀀󠄀゙(22回繰り返し).txt](img/use-ascii-5.png)
「𛀀󠄀゙」の詳細
| コードポイント | U+1B000 | U+E0100 | U+3099 |
|---|
| UTF-8バイト列 | F0 9B 80 80 | F3 A0 84 80 | E3 82 99 |
|---|
| UTF-16代用対表現 | U+D82C | U+DC00 | U+DB40 | U+DD00 | U+3099 |
|---|
| UTF-16LEバイト列 | 2C D8 | 00 DC | 40 DB | 00 DD | 99 30 |
|---|
| CESU-8バイト列 | ED A0 AC | ED B0 80 | ED AD 80 | ED B4 80 | E3 82 99 |
|---|
Windowsのパス最大長は通常はUTF-16LE換算で260文字、Linuxのファイル名最大長は255バイトです。「𛀀󠄀゙」はWindows NTFSにとって五文字分、UTF-8のファイルシステムにとって11バイト分です。長めの非ASCIIファイル名をWindows上で書庫に圧縮すると、別のOS上で書庫から展開できなくなったり、ファイルにアクセスできなくなったりする可能性があります。
Unicodeは言語環境の差異による文字化けを根絶しますが、かわりに実装水準の違いによるトラブルをもたらします。ターゲットをUnicode対応機種に限る場合でも、ファイル名に非ASCII文字を使うのは避けたほうが無難です。
たとえばファイル名に混入するゼロ幅スペースは極端に発見しづらい参照ミスの原因になりうるし、古いOSでは基本多言語面の範囲外文字は「豆腐」として表示されるので見分けがつきません。不可視の空白類や制御文字は予想外に多く、それを用いた悪戯も知られています(たとえば書字方向変更)。「見えない文字」は潜在的に危険なので、ASCII空白文字の使用も推奨できません。
すべてのASCII印字可能文字が安全であるわけではありません
結論からいえば、かろうじて安全といえるのは英数字とアンダースコア(_)くらいです。ファイル名の先頭や末尾以外なら、ハイフンマイナス(-)も許容範囲でしょうか。
- ファイル名の先頭のハイフンマイナスは、コマンドライン引数として誤解釈され得ます。
- 「
& ^ % ( )」などはcmd.exeではエスケープ対象であり、バッチ処理を書きづらくします。
- 「
\ : * ? " < > |」は、Unix系OSではファイル名として使うことができてしまいます。
- ピリオドや空白の使用を許容すると、「
a.bms .exe」などの悪戯も可能になります。
「ファイル名 - 脚注2」の通り、Windowsにおいてファイル名末尾の空白は安全ではありません。たとえば外部アーカイバーの場合、展開できなかったり(これvsこれ)、コマンドプロンプト以外では削除できないフォルダーが作られたりします(旧版WinRARでサブフォルダーに展開時)。
Webからの参照が面倒な名前の例: <a href="%23WAV06%20&copy%3B.%20%20%20.rar">
- この書庫名を
href属性値に直接書くと、ページ内リンクとして解釈されてしまいます。
- ファイル名に「
& # ;」を許容すると、文字参照で悪戯できます(「‮」など)。
- ファイル名に「
%」を許容すると、「%2E%2E%2Fa.zip」で「../a.zip」など。
- ファイル名に「
」を許容すると、「<a href=#WAV06 title=big.wav>」とかなんとか。
- ファイル名に「
+ -」を許容すると、charsetが不正なHTMLでUTF-7なXSS遊びとか。
これらは問題になりうる名前の一例です。もしもすべてのWeb管理者が、HTMLをUTF-8で符号化し、属性値を必ず引用符で括り、危険な記号をすべてエスケープし、アップロードされるファイルの名前を無害化する処置を怠らず、名前に関する既知のテストケースをすべてクリアしているなら、「文字以外の機能を持ちうる記号」の使用をためらう理由はありません。
じつのところ、OSには予約名というものがあるし、Webの属性値には異なるいくつかの表現がありえますから(たとえばBase64)、英数字のみを使う場合でさえ、リスクを完全に回避できるわけではありません。しかしBMSにとって本質的でないこのような問題に、趣味の開発者の貴重な労力を割いてもらうというのは、あまり賢明な選択ではありません。
Windows上で「#WAV01 abc.wav」は実際の「ABC.WAV」を参照できてしまいますが、Linuxでは大文字小文字が区別されます。AngolmoisはWindowsとの互換性を考慮し、明示的に大文字小文字を同一視します。しかし、BMS著者はそれを当てにするべきではありません。BMSテキスト上で参照されるファイル名と、実際のファイル名は、大文字小文字まで一致させてください。
打ち切り
完